En resumen, porque DeepMind tiene TPU . Montones, montones de TPU.
De lejos, la parte más lenta del proceso de entrenamiento es generar juegos de auto-juego . DeepMind usó 5000 TPU para generar juegos de auto-juego, que es una gran potencia de procesamiento. Mientras tanto, Lc0 recurre al poder de procesamiento de clientes voluntarios, que es mucho más lento.
Del artículo de DeepMind publicado en diciembre de 2017 (el énfasis es mío):
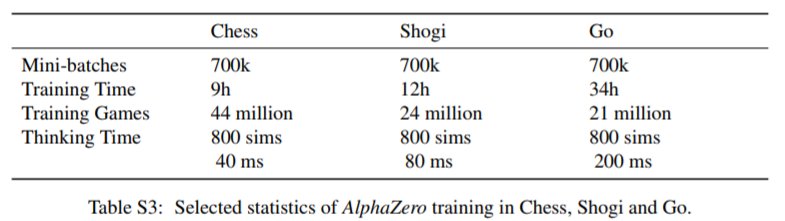
Entrenamos una instancia separada de AlphaZero para cada juego. El entrenamiento se llevó a cabo durante 700,000 pasos (mini lotes de tamaño 4096) a partir de parámetros inicializados aleatoriamente, utilizando 5,000 TPU de primera generación para generar juegos de auto-reproducción y 64 TPU de segunda generación para entrenar las redes neuronales.
Para lograr el nivel de rendimiento que AlphaZero obtuvo contra la versión 8 de Stockfish (subóptimamente sintonizada), la ejecución de entrenamiento tomó alrededor de 9 horas y 44 millones de -Juegos de ajedrez:
Mientras tanto, el proyecto Lc0 se inició en algún momento de enero de 2018 y en abril de 2018, solo habían generado 8.2 millones de los 44 millones de juegos necesarios . Creo que estaban generando alrededor de 200.000 juegos por día en ese momento.
También encontraron muchos errores en el proceso y estaban resolviendo muchas cosas a medida que avanzaban, así que cuando se realizó el primer entrenamiento estancado, la mejor red no era tan buena como AlphaZero. Desde entonces, el proyecto Lc0 ha reiniciado la ejecución de entrenamiento varias veces:
- antigua principal: la ejecución "principal" original de 192x15, utilizando el motor
lczero.exe original. Terminó en agosto de 2018, siendo la última red ID595. (Sin embargo, parece que estas redes ya no aparecen en la lista. Los primeros ID al final de la lista de redes parecen ser estas redes de prueba).
- test10 : la ejecución de prueba original de 256 x 20. Se trataba de una canalización independiente que utilizaba un motor
lc0.exe completamente reescrito que era mucho más rápido en la generación de juegos de auto-juego. La numeración neta para esta ejecución comenzó con ID10000 el 27 de junio de 2018 y finalizó con ID11262 el 30 de agosto de 2018. - test20 : una ejecución con varios cambios, comenzando con ID20001 el 30 de agosto de 2018 y finalizando con ID22201 el 16 de noviembre de 2018.
- test30 : una prueba de ejecución varias ideas nuevas, comenzando con ID30001 el 9 de septiembre de 2018. A partir del 14 de enero de 2019, la mejor red era ID32598.
- test40 : el 6 de diciembre de El documento AlphaZero de 2018 reveló muchas diferencias entre lo que hizo DeepMind y lo que hizo Lc0, y parece que una nueva ejecución de prueba comenzó con ID40001 el 8 de enero de 2019. A partir de El 14 de enero de 2019, la mejor red fue ID40202.
Para tener una idea de lo bien que le está yendo a Lc0 en comparación con AlphaZero, es más útil observar el Elo con respecto al número total de juegos generados, no tiempo transcurrido. Así es como se ve el gráfico para todo el proyecto Lc0 al 14 de enero de 2019 (tenga en cuenta que se trata de Elo de juego automático, que está inflado en comparación con el Elo real):
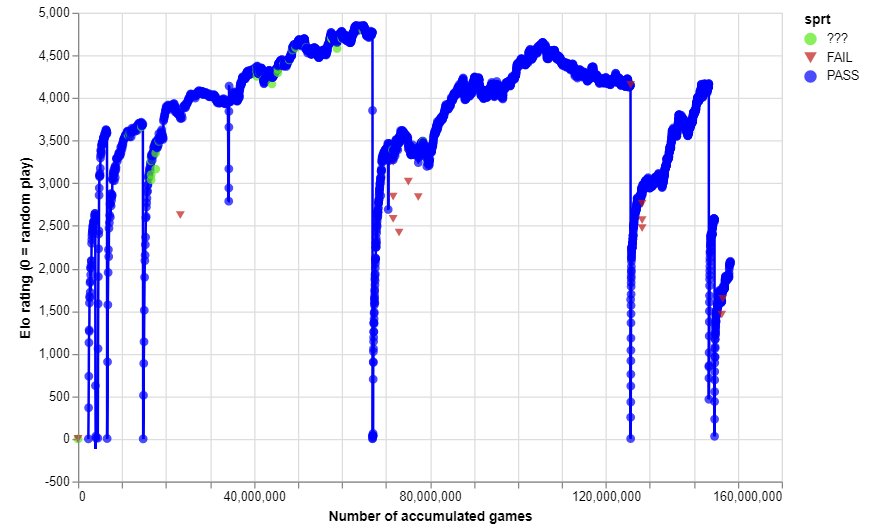
Como puede ver, han reiniciado la ejecución de entrenamiento muchas veces. También hubo una serie de mini-restablecimientos de arranque durante la ejecución principal original para corregir algunos errores críticos, y también hubo una prueba35 temporal para probar los ajustes de configuración recientemente revelados de el documento AlphaGo de diciembre de 2018. ¡Sí, esto no es confuso en absoluto! (/ s)
Hay muchos cálculos y gráficos en esta hoja de cálculo aquí que comparan el rendimiento de lc0 con AlphaZero. Por ejemplo, aquí está el gráfico de la primera ejecución principal anterior (en la pestaña "Gráficos"):
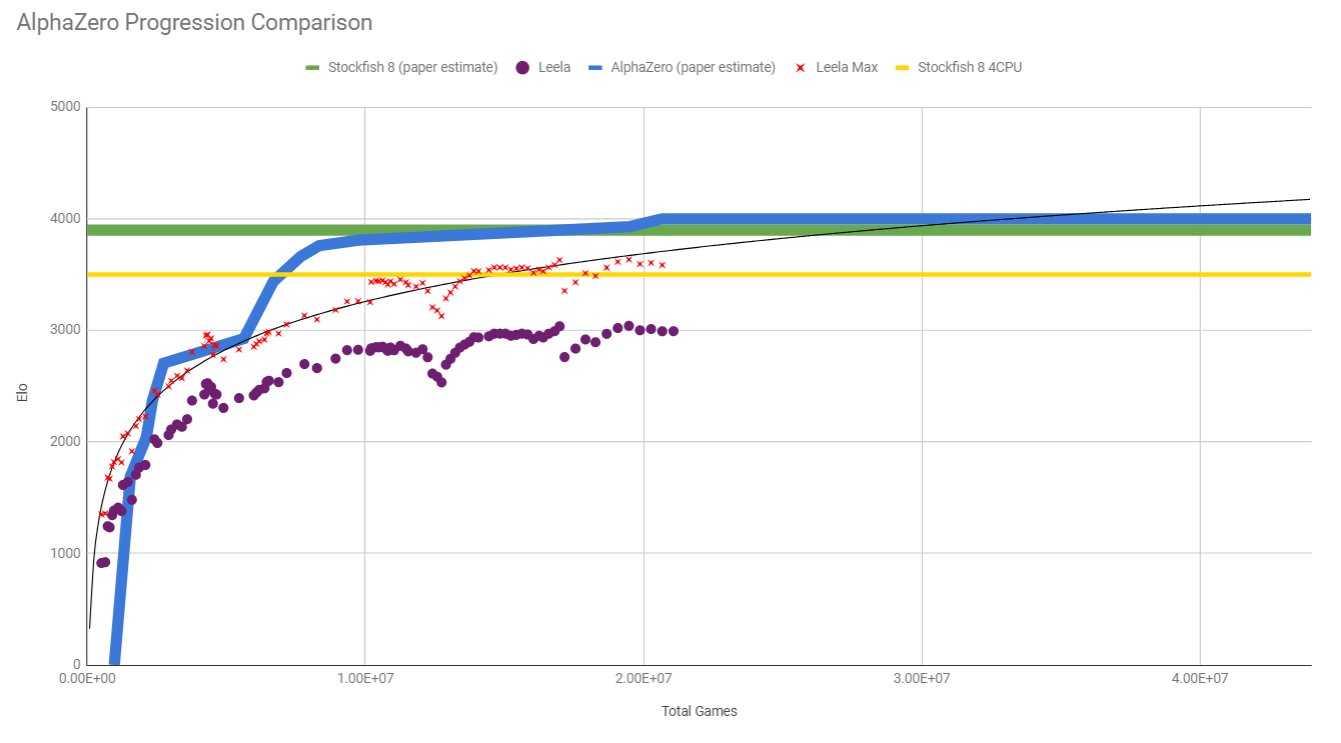 Desde ese enlace, una explicación de lo que "Leela Max" es:
Desde ese enlace, una explicación de lo que "Leela Max" es:
"Leela Max" es el rendimiento máximo teórico de Leela cuando se le da hardware y / o tiempo hasta el punto de rendimientos absolutamente disminuidos. Puede ser más comparable a AlphaZero, ya que AlphaZero operaba en 4.8 millones de nodos por movimiento, mientras que una configuración convencional solo obtiene una pequeña fracción de eso.
En estos días, el auto- La velocidad de generación de juegos es mucho más rápida de lo que era al principio. Al 14 de enero de 2019, parece que el proyecto genera aproximadamente 1,5 millones de juegos por día. Pero a esta velocidad, todavía tomará un mes lograr lo que DeepMind logró en 9 horas. En realidad, es más como el doble de tiempo si los juegos de entrenamiento se desvían hacia dos carreras separadas.